



在 LLaMA-Factory 微调多模态模型(比如 LLaVA 系列)时,Freeze vision tower 和 Freeze multi-modal projector 这两个参数控制的是视觉部分的哪些模块会被更新,直接影响训练速度、显存占用以及模型的微调效果。
我给你拆开解释一下它们分别代表什么以及怎么配。
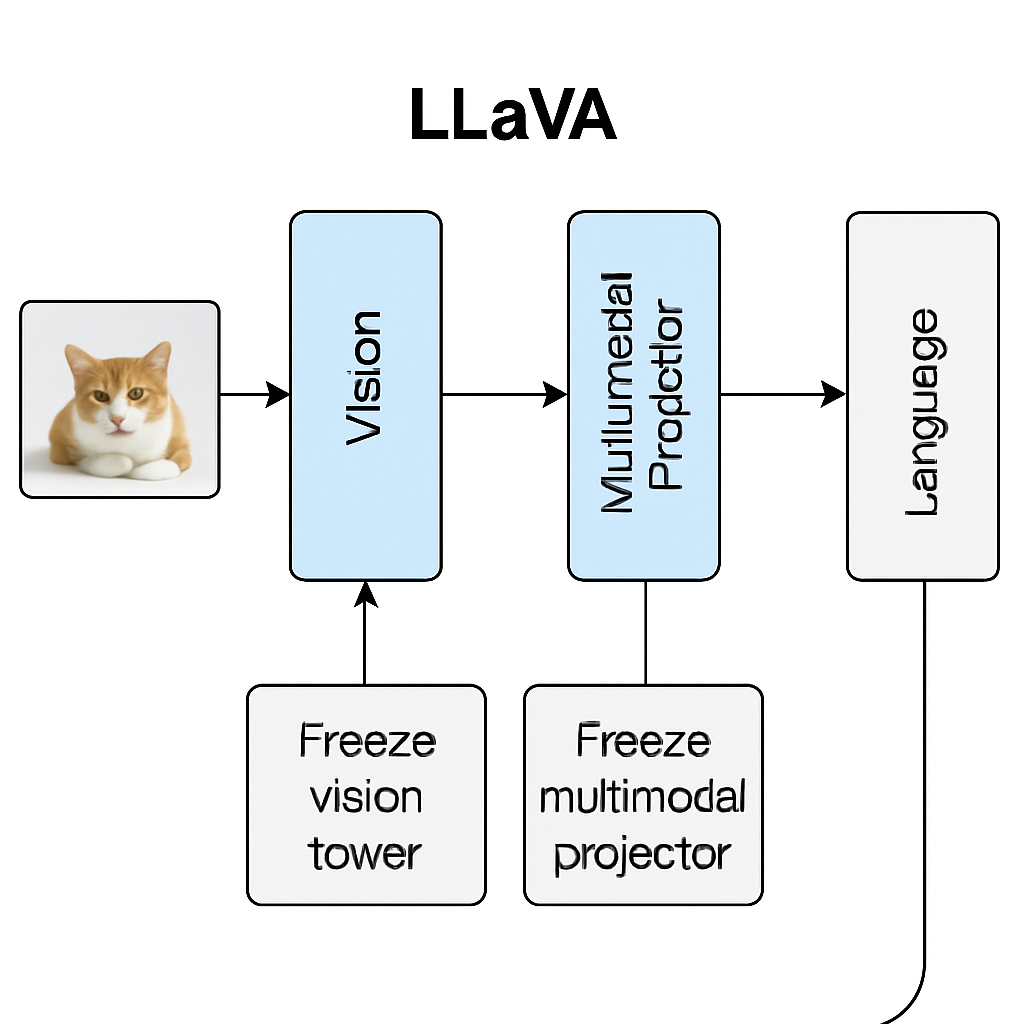
1. Freeze vision tower
含义
Vision Tower 是多模态模型里的视觉编码器,通常是 CLIP 的 ViT 模型(如
openai/clip-vit-large-patch14)。它负责把图片转成视觉特征向量。
“Freeze”表示在微调过程中不更新它的参数,只用预训练的权重。
配置建议
冻结 (
True):好处:显存占用少、训练快,不容易过拟合;适合数据集小(比如几万条以下)或只是想适配任务。
坏处:视觉特征能力完全依赖原预训练模型,对特定任务的视觉细节适配有限。
不冻结 (
False):好处:视觉特征可以更贴合任务需求(比如你有很多和领域相关的图片)。
坏处:显存和算力需求大幅增加(几倍),数据少时容易过拟合。
2. Freeze multi-modal projector
含义
Multi-modal Projector 是连接视觉编码器和语言模型的投影层,通常是一个 MLP(或线性层),把视觉向量映射到语言模型可理解的维度空间。
冻结它就意味着不调整图像特征到文本空间的映射方式。
配置建议
冻结 (
True):好处:如果视觉塔没动,冻结它也能保持稳定训练,不会破坏已有的特征映射。
坏处:任务相关的视觉-文本对齐能力无法改进。
不冻结 (
False):好处:可以针对任务数据微调视觉-语言对齐方式,往往收益明显。
坏处:会多一些计算,但比解冻 vision tower 成本低很多。
常见组合建议
💡 经验之谈:
如果你用 LLaMA-Factory 微调 LLaVA 这种多模态模型,且数据不多(<10w 样本),建议:
Freeze vision tower = True
Freeze multi-modal projector = False这样成本低且对任务有针对性提升。
等你有更多数据和显存,再考虑解冻 vision tower。
评论区