



学习率(Learning Rate, LR)是深度学习里最关键的超参数之一,在大模型微调(fine-tuning)中它基本决定了模型参数更新的“步长”——每次梯度下降的时候,参数会沿着梯度方向走多远。
你可以把它理解成:
学习率大 → 模型学得快,但容易“迈太大步摔跟头”,甚至直接跳过最优点。
学习率小 → 模型学得稳,但可能需要很久才收敛,甚至卡在局部最优。
1. 学习率在大模型微调中的作用
微调大模型和从零训练不同,因为:
大模型的权重已经经过了海量预训练,我们不希望破坏原有的知识。
任务微调时,我们更多是轻微调整权重,让它适配新任务。
所以,微调时的学习率通常远小于从零训练的学习率,否则会导致“灾难性遗忘”(catastrophic forgetting)——模型忘掉原本的能力。
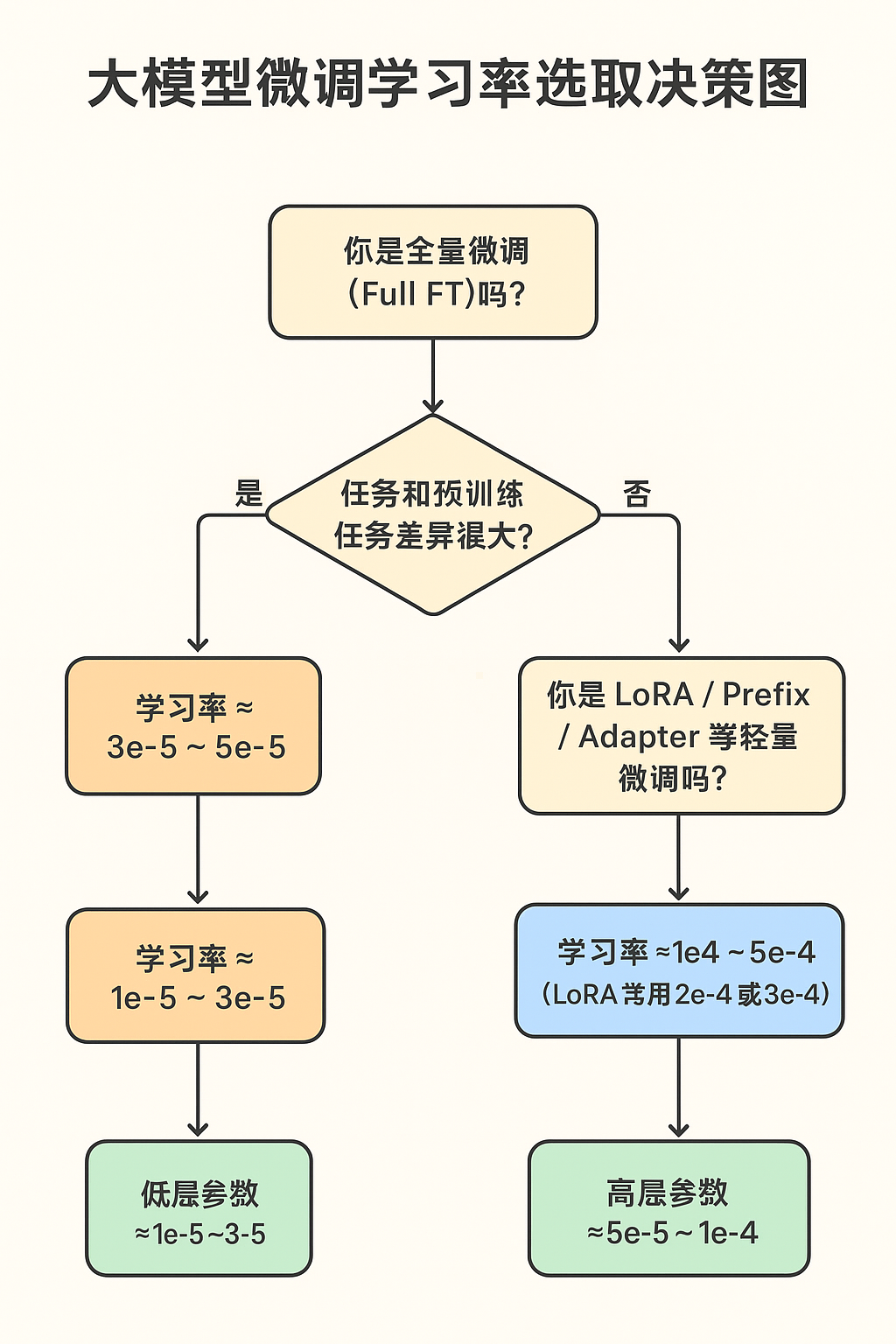
2. 常见的学习率设置原则
(1)全量微调(Full Fine-tuning)
适用场景:任务和预训练任务差异很大。
学习率范围:1e-5 ~ 5e-5(AdamW 等优化器)。
原因:需要对整个模型进行调整,但还是不能太大。
(2)LoRA / Prefix-tuning / Adapter 等轻量微调
适用场景:任务和预训练任务差异不大,参数冻结大部分层。
学习率范围:1e-4 ~ 5e-4(因为只训练很少的参数,可以更大)。
经验:LoRA 通常比全量微调 LR 大一个量级。
(3)冻结部分层
适用场景:保留底层特征提取能力,只改高层。
学习率:低层 1e-5 左右,高层 1e-4 左右(分组学习率)。
3. 细节调优技巧
Warmup(热身阶段):刚开始用较小 LR(比如最终 LR 的 10%),再逐渐升到目标值,可以避免训练初期梯度爆炸。
学习率调度器(Scheduler):如 Cosine decay、Linear decay,让学习率在训练中逐步下降,提高收敛稳定性。
分层学习率(Layer-wise LR decay):越靠近输入的层,学习率越小;越靠近输出的层,学习率越大。
4. 如果不知道怎么设
可以用一个小的验证集快速试:
先设一个偏大的值(比如 LoRA 用 5e-4,全量用 5e-5)。
看前几个 epoch loss 的变化:
loss 不降甚至震荡 → 学习率太大。
loss 缓慢下降 → 学习率可能太小。
最后在合适区间内用网格搜索或逐步缩放。
评论区