



在机器学习和深度学习中,loss曲线(损失函数随训练过程的变化曲线)是一个非常重要的诊断工具。
它不仅能告诉你模型的拟合程度,还能帮助发现训练中出现的欠拟合、过拟合、学习率不合适等问题。
1. 要画哪些曲线
通常我们会同时绘制:
训练集损失(train loss)
验证集损失(validation loss)
例子:
x轴:训练迭代次数(epoch 或 step)
y轴:loss 数值
曲线1:train loss
曲线2:val loss
2. 如何解读不同形状
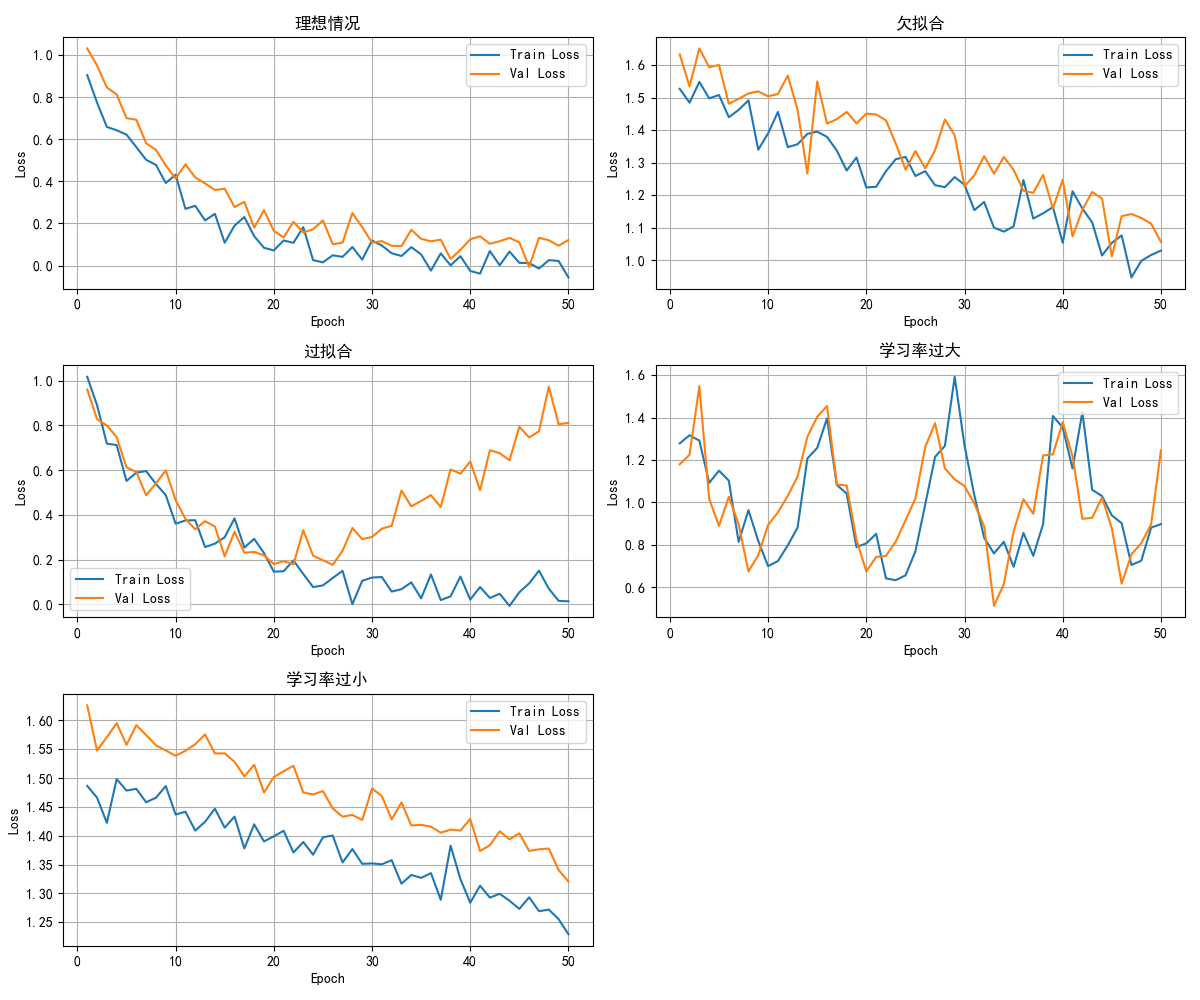
2.1 正常情况(理想状态)
train loss 随着训练稳步下降
val loss 先下降,然后趋于稳定,和 train loss 差距不大
✅ 说明模型收敛良好,没有明显过拟合或欠拟合。
2.2 欠拟合(underfitting)
train loss 高且下降缓慢
val loss 同样高,没有明显下降趋势
原因:模型容量不足、特征不够、学习率过低、训练轮数太少。
解决:增加模型复杂度(更多参数、更深网络)
加大训练时间
提高学习率(如果loss下降过慢)
2.3 过拟合(overfitting)
train loss 持续下降并很低
val loss 在某个点后开始上升(两者差距越来越大)
原因:模型在训练集上学得太好,但泛化能力差。
解决:使用正则化(L2、Dropout、数据增强等)
提前停止(early stopping)
增加训练数据
2.4 学习率过大
train loss 波动很大甚至不下降
val loss 同样波动且不收敛
原因:参数更新步伐太大,模型来回“跳”。
解决:降低学习率
2.5 学习率过小
train loss 缓慢下降,很长时间没什么变化
val loss 也缓慢变化
解决:增大学习率
使用学习率调度(warmup、cosine decay等)
3. 最佳实践
同时看loss和accuracy:loss能看出训练过程的细节,accuracy能看出性能直观变化。
关注转折点:val loss开始上升的点,往往是过拟合的开始。
保存最优模型:按val loss最低时保存权重(避免过拟合后性能下降)。
分阶段调参:先用较大学习率找大致收敛区间,再细调。
评论区